domingo, 3 de octubre de 2010
martes, 28 de septiembre de 2010
DIAGRAMA DE ARBOL
Un diagrama de árbol es una representación gráfica de un experimento que consta de r pasos, donde cada uno de los pasos tiene un número finito de maneras de ser llevado a cabo.
Ejemplo:
Una universidad tiene de tres facultades:

¿Probabilidad de encontrar una alumna de la primera facultad?


¿Probabilidad de encontrar un alumno varón?


Ejemplo:
Una universidad tiene de tres facultades:
- La 1ª con el 50% de estudiantes.
- La 2ª con el 25% de estudiantes.
- La 3ª con el 25% de estudiantes.

¿Probabilidad de encontrar una alumna de la primera facultad?

¿Probabilidad de encontrar un alumno varón?

sábado, 25 de septiembre de 2010
TAMAÑO MUESTRAL PARA UNA MUESTRA INFINITA
Con estos estudios pretendemos hacer inferencias a valores poblacionales (proporciones, medias) a partir de una muestra.
A.1. Estimar una proporción:
Si deseamos estimar una proporción, debemos saber:
Seguridad = 95%; Precisión = 3%: Proporción esperada = asumamos que puede ser próxima al 5%; si no tuviésemos ninguna idea de dicha proporción utilizaríamos el valor p = 0,5 (50%) que maximiza el tamaño muestral:


 donde:
donde:
Seguridad = 95%; Precisión = 3%; proporción esperada = asumamos que puede ser próxima al 5% ; si no tuviese ninguna idea de dicha proporción utilizaríamos el valor p = 0.5 (50%) que maximiza el tamaño muestral.
 Según diferentes seguridades el coeficiente de Za varía, así:
Según diferentes seguridades el coeficiente de Za varía, así:
Si deseamos estimar una media: debemos saber:
 Ejemplo: Si deseamos conocer la media de la glucemia basal de una población, con una seguridad del 95 % y una precisión de ± 3 mg/dl y tenemos información por un estudio piloto o revisión bibliográfica que la varianza es de 250 mg/dl
Ejemplo: Si deseamos conocer la media de la glucemia basal de una población, con una seguridad del 95 % y una precisión de ± 3 mg/dl y tenemos información por un estudio piloto o revisión bibliográfica que la varianza es de 250 mg/dl
 Si la población es finita, como previamente se señaló, es decir conocemos el total de la población y desearíamos saber cuantos del total tendríamos que estudiar, la respuesta sería:
Si la población es finita, como previamente se señaló, es decir conocemos el total de la población y desearíamos saber cuantos del total tendríamos que estudiar, la respuesta sería:

A.1. Estimar una proporción:
Si deseamos estimar una proporción, debemos saber:
- El nivel de confianza o seguridad (1-a ). El nivel de confianza prefijado da lugar a un coeficiente (Za ). Para una seguridad del 95% = 1.96, para una seguridad del 99% = 2.58.
- La precisión que deseamos para nuestro estudio.
- Una idea del valor aproximado del parámetro que queremos medir (en este caso una proporción). Esta idea se puede obtener revisando la literatura, por estudio pilotos previos. En caso de no tener dicha información utilizaremos el valor p = 0.5 (50%).
Seguridad = 95%; Precisión = 3%: Proporción esperada = asumamos que puede ser próxima al 5%; si no tuviésemos ninguna idea de dicha proporción utilizaríamos el valor p = 0,5 (50%) que maximiza el tamaño muestral:
donde:
- Za 2 = 1.962 (ya que la seguridad es del 95%)
- p = proporción esperada (en este caso 5% = 0.05)
- q = 1 – p (en este caso 1 – 0.05 = 0.95)
- d = precisión (en este caso deseamos un 3%)
Si la población es finita, es decir conocemos el total de la población y deseásemos saber cuántos del total tendremos que estudiar la respuesta seria:
- N = Total de la población
- Za2 = 1.962 (si la seguridad es del 95%)
- p = proporción esperada (en este caso 5% = 0.05)
- q = 1 – p (en este caso 1-0.05 = 0.95)
- d = precisión (en este caso deseamos un 3%).
Seguridad = 95%; Precisión = 3%; proporción esperada = asumamos que puede ser próxima al 5% ; si no tuviese ninguna idea de dicha proporción utilizaríamos el valor p = 0.5 (50%) que maximiza el tamaño muestral.
- Si la seguridad Za fuese del 90% el coeficiente sería 1.645
- Si la seguridad Za fuese del 95% el coeficiente sería 1.96
- Si la seguridad Za fuese del 97.5% el coeficiente sería 2.24
- Si la seguridad Za fuese del 99% el coeficiente sería 2.576
Si deseamos estimar una media: debemos saber:
- El nivel de confianza o seguridad (1-a ). El nivel de confianza prefijado da lugar a un coeficiente (Za ). Para una seguridad del 95% = 1.96; para una seguridad del 99% = 2.58.
- La precisión con que se desea estimar el parámetro (2 * d es la amplitud del intervalo de confianza).
- Una idea de la varianza S2 de la distribución de la variable cuantitativa que se supone existe en la población.
AREA BAJO LA CURVA
Distribución normal estándar

Esta curva "de campana" es la distribución normal estándar.
Esto te dice qué parte de la población está dentro de "Z" desviaciones estándar de la media.
En lugar de una tabla LARGA, hemos puesto los incrementos de 0.1 hacia abajo, y los de 0.01 de lado.
Por ejemplo, para saber el área debajo de la curva entre 0 y 0.45, ve a la fila de 0.4, y sigue de lado hasta 0.45, allí pone 0.1736
Como la curva es simétrica, la tabla vale para ir en las dos direcciones, así que 0.45 negativo también tiene un área de 0.1736
AREAS BAJO LA CURVA NORMAL
No importa cuáles sean los valores de la para una distribución de probabilidad normal, el área total bajo la curva es 1.00, de manera que podemos pensar en áreas bajo la curva como si fueran probabilidades. Matemáticamente es verdad que:
1.Aproximadamente 68% de todos los valores de una población normalmente distribuida se encuentra dentro de
2. Aproximadamente 95.5 % de todos los valores de una población normalmente distribuida se encuentra dentro de
3. Aproximadamente 99.7 % de todos los valores de una población normalmente distribuida se encuentra dentro de
USO DE LA TABLA DE DISTRIBUCIÓN DE PROBABILIDAD NORMAL ESTÁNDAR
DISTRIBUCIÓN DE PROBABILIDAD NORMAL ESTÁNDARÁreas bajo la distribución de probabilidad Normal Estándar entre la media y valores positivos de Z m = 0 y s²=1
| Z | 0.00 | 0.01 | 0.02 | 0.03 | 0.04 | 0.05 | 0.06 | 0.07 | 0.08 | 0.09 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.0 | 0.0000 | 0.0040 | 0.0080 | 0.0120 | 0.0160 | 0.0199 | 0.0239 | 0.0279 | 0.0319 | 0.0359 |
| 0.1 | 0.0398 | 0.0438 | 0.0478 | 0.0517 | 0.0557 | 0.0596 | 0.0636 | 0.0675 | 0.0714 | 0.0753 |
| 0.2 | 0.0793 | 0.0832 | 0.0871 | 0.0910 | 0.0948 | 0.0987 | 0.1026 | 0.1064 | 0.1103 | 0.1141 |
| 0.3 | 0.1179 | 0.1217 | 0.1255 | 0.1293 | 0.1331 | 0.1368 | 0.1406 | 0.1443 | 0.1480 | 0.1517 |
| 0.4 | 0.1554 | 0.1591 | 0.1628 | 0.1664 | 0.1700 | 0.1736 | 0.1772 | 0.1808 | 0.1844 | 0.1879 |
| 0.5 | 0.1915 | 0.1950 | 0.1985 | 0.2019 | 0.2054 | 0.2088 | 0.2123 | 0.2157 | 0.2190 | 0.2224 |
| 0.6 | 0.2257 | 0.2291 | 0.2324 | 0.2357 | 0.2389 | 0.2422 | 0.2454 | 0.2486 | 0.2517 | 0.2549 |
| 0.7 | 0.2580 | 0.2611 | 0.2642 | 0.2673 | 0.2704 | 0.2734 | 0.2764 | 0.2794 | 0.2823 | 0.2852 |
| 0.8 | 0.2881 | 0.2910 | 0.2939 | 0.2967 | 0.2995 | 0.3023 | 0.3051 | 0.3078 | 0.3106 | 0.3133 |
| 0.9 | 0.3159 | 0.3186 | 0.3212 | 0.3238 | 0.3264 | 0.3289 | 0.3315 | 0.3340 | 0.3365 | 0.3389 |
| 1.0 | 0.3413 | 0.3438 | 0.3461 | 0.3485 | 0.3508 | 0.3531 | 0.3554 | 0.3577 | 0.3599 | 0.3621 |
| 1.1 | 0.3643 | 0.3665 | 0.3686 | 0.3708 | 0.3729 | 0.3749 | 0.3770 | 0.3790 | 0.3810 | 0.3830 |
| 1.2 | 0.3849 | 0.3869 | 0.3888 | 0.3907 | 0.3925 | 0.3944 | 0.3962 | 0.3980 | 0.3997 | 0.4015 |
| 1.3 | 0.4032 | 0.4049 | 0.4066 | 0.4082 | 0.4099 | 0.4115 | 0.4131 | 0.4147 | 0.4162 | 0.4177 |
| 1.4 | 0.4192 | 0.4207 | 0.4222 | 0.4236 | 0.4251 | 0.4265 | 0.4279 | 0.4292 | 0.4306 | 0.4319 |
| 1.5 | 0.4332 | 0.4345 | 0.4357 | 0.4370 | 0.4382 | 0.4394 | 0.4406 | 0.4418 | 0.4429 | 0.4441 |
| 1.6 | 0.4452 | 0.4463 | 0.4474 | 0.4484 | 0.4495 | 0.4505 | 0.4515 | 0.4525 | 0.4535 | 0.4545 |
| 1.7 | 0.4554 | 0.4564 | 0.4573 | 0.4582 | 0.4591 | 0.4599 | 0.4608 | 0.4616 | 0.4625 | 0.4633 |
| 1.8 | 0.4641 | 0.4649 | 0.4656 | 0.4664 | 0.4671 | 0.4678 | 0.4686 | 0.4693 | 0.4699 | 0.4706 |
| 1.9 | 0.4713 | 0.4719 | 0.4726 | 0.4732 | 0.4738 | 0.4744 | 0.4750 | 0.4756 | 0.4761 | 0.4767 |
| 2.0 | 0.4772 | 0.4778 | 0.4783 | 0.4788 | 0.4793 | 0.4798 | 0.4803 | 0.4808 | 0.4812 | 0.4817 |
| 2.1 | 0.4821 | 0.4826 | 0.4830 | 0.4834 | 0.4838 | 0.4842 | 0.4846 | 0.4850 | 0.4854 | 0.4857 |
| 2.2 | 0.4861 | 0.4864 | 0.4868 | 0.4871 | 0.4875 | 0.4878 | 0.4881 | 0.4884 | 0.4887 | 0.4890 |
| 2.3 | 0.4893 | 0.4896 | 0.4898 | 0.4901 | 0.4904 | 0.4906 | 0.4909 | 0.4911 | 0.4913 | 0.4916 |
| 2.4 | 0.4918 | 0.4920 | 0.4922 | 0.4925 | 0.4927 | 0.4929 | 0.4931 | 0.4932 | 0.4934 | 0.4936 |
| 2.5 | 0.4938 | 0.4940 | 0.4941 | 0.4943 | 0.4945 | 0.4946 | 0.4948 | 0.4949 | 0.4951 | 0.4952 |
| 2.6 | 0.4953 | 0.4955 | 0.4956 | 0.4957 | 0.4959 | 0.4960 | 0.4961 | 0.4962 | 0.4963 | 0.4964 |
| 2.7 | 0.4965 | 0.4966 | 0.4967 | 0.4968 | 0.4969 | 0.4970 | 0.4971 | 0.4972 | 0.4973 | 0.4974 |
| 2.8 | 0.4974 | 0.4975 | 0.4976 | 0.4977 | 0.4977 | 0.4978 | 0.4979 | 0.4979 | 0.4980 | 0.4981 |
| 2.9 | 0.4981 | 0.4982 | 0.4982 | 0.4983 | 0.4984 | 0.4984 | 0.4985 | 0.4985 | 0.4986 | 0.4986 |
| 3.0 | 0.4987 | 0.4987 | 0.4987 | 0.4988 | 0.4988 | 0.4989 | 0.4989 | 0.4989 | 0.4990 | 0.4990 |
X = valor de la variable aleatoria que nos preocupa
Z = número de desviaciones estándar que hay desde x a la media de la distribución
Utilizamos Z en lugar del ‘ número de desviaciones estándar’ porque las variables aleatorias normalmente distribuidas tienen muchas unidades diferentes de medición: dólares, pulgadas, partes por millón, kilogramos, segundos. Como vamos a utilizar una tabla, la tabla I, hablamos en términos de unidades estándar (que en realidad significa desviaciones estándar), y denotamos a éstas con el símbolo z.
X
-25 0 25 50 75 100 125
----------------------------------------- Z =
-3 -2 -1 0 1 2 3
La tabla representa las probabilidades o áreas bajo la curva normal calculadas desde la = 0) hasta los valores transformados de interés Z.
Sólo se enumeran entradas positivas de Z en la tabla , puesto que para una distribución simétrica de este tipo con una media de cero, el área que va desde la media hasta +Z (es decir, Z desviaciones estándar por encima de la media) debe ser idéntica al área que va desde la media hasta –Z (es decir, Z desviaciones estándar por debajo de la media).
También podemos encontrar la tabla que indica el área bajo la curva normal estándar que corresponde a P(Z < z) para valores de z que van de –3.49 a 3.49.
Al usar la tabla observamos que todos los valores Z deben registrarse con hasta dos lugares decimales. Por tanto, nuestro valor de interés particular Z se registra como +.2. para leer el área de probabilidad bajo la curva desde la media hasta Z = +.20, podemos recorrer hacia abajo la columna Z de la tabla hasta que ubiquemos el valor de interés Z. Así pues, nos detenemos en la fila Z = .2. A continuación, leemos esta fila hasta que intersecamos la columna que contiene el lugar de centésimas del valor Z. Por lo tanto, en la tabla, la probabilidad tabulada para Z = 0.20 corresponde a la intersección de la fila Z = .2 con la columna Z = .00 como se muestra.
Z | .00 | .01 | .02 | .03 | .04 | .05 | .06 | .07 | .08 | .09 |
0.0 | 0.00000 | 0.00399 | 0.00798 | 0.01197 | 0.01595 | 0.01994 | 0.02392 | 0.02790 | 0.03188 | 0.03586 |
0.1 | 0.03983 | 0.04380 | 0.04776 | 0.05172 | 0.05567 | 0.05962 | 0.06356 | 0.06749 | 0.07142 | 0.07535 |
0.2 | 0.07926 | 0.08317 | 0.08706 | 0.09095 | 0.09483 | 0.09871 | 0.10257 | 0.10642 | 0.11026 | 0.11409 |
DISTRIBUCION BINOMIAL
Supongamos que un experimento aleatorio tiene las siguientes características:
La variable binomial es una variable aleatoria discreta, sólo puede tomar los valores 0, 1, 2, 3, 4, ..., n suponiendo que se han realizado n pruebas. Como hay que considerar todas las maneras posibles de obtener k-éxitos y (n-k) fracasos debemos calcular éstas por combinaciones (número combinatorio n sobre k).
La distribución Binomial se suele representar por B(n,p) siendo n y p los parámetros de dicha distribución.
Función de Probabilidad de la v.a. Binomial
Función de probabilidad de la distribución Binomial o también denominada función de la distribución de Bernoulli (para n=1). Verificándose: 0 £ p £ 1

Todo experimento que tenga estas características diremos que sigue el modelo de la distribución Binomial. A la variable X que expresa el número de éxitos obtenidos en cada prueba del experimento, la llamaremos variable aleatoria binomial.
- En cada prueba del experimento sólo son posibles dos resultados: el suceso A (éxito) y su contrario`A (fracaso).
- El resultado obtenido en cada prueba es independiente de los resultados obtenidos anteriormente.
- La probabilidad del suceso A es constante, la representamos por p, y no varía de una prueba a otra. La probabilidad de `A es 1- p y la representamos por q .
- El experimento consta de un número n de pruebas.
La variable binomial es una variable aleatoria discreta, sólo puede tomar los valores 0, 1, 2, 3, 4, ..., n suponiendo que se han realizado n pruebas. Como hay que considerar todas las maneras posibles de obtener k-éxitos y (n-k) fracasos debemos calcular éstas por combinaciones (número combinatorio n sobre k).
La distribución Binomial se suele representar por B(n,p) siendo n y p los parámetros de dicha distribución.
Función de Probabilidad de la v.a. Binomial
Función de probabilidad de la distribución Binomial o también denominada función de la distribución de Bernoulli (para n=1). Verificándose: 0 £ p £ 1
Parámetros de la Distribución Binomial
Como el cálculo de estas probabilidades puede resultar algo tedioso se han construido tablas para algunos valores de n y p que nos facilitan el trabajo.
Ver Tabla de la Función de Probabilidad de la Binomial
Función de Distribución de la v.a. Binomial
siendo k el mayor número entero menor o igual a xi.
Esta función de distribución proporciona, para cada número real xi, la probabilidad de que la variable X tome valores menores o iguales que xi.
El cálculo de las F(x) = p( X £x) puede resultar laborioso, por ello se han construido tablas para algunos valores de n y p que nos facilitan el trabajo.



Sea X una variable aleatoria discreta correspondiente a una distribución binomial.
Ejemplo 1
Una máquina fabrica una determinada pieza y se sabe que produce un 7 por 1000 de piezas defectuosas. Hallar la probabilidad de que al examinar 50 piezas sólo haya una defectuosa.Solución :Se trata de una distribución binomial de parámetros B(50, 0'007) y debemos calcular la probabilidad p(X=1).

Ejemplo 2
La probabilidad de éxito de una determinada vacuna es 0,72. Calcula la probabilidad de a que una vez administrada a 15 pacientes:
a) Ninguno sufra la enfermedad
b) Todos sufran la enfermedad
c) Dos de ellos contraigan la enfermedadSolución :Se trata de una distribución binomial de parámetros B(15, 0'72)

Ejemplo 3
La probabilidad de que el carburador de un coche salga de fábrica defectuoso es del 4 por 100. Hallar :
a) El número de carburadores defectuosos esperados en un lote de 1000
b) La varianza y la desviación típica.Solución :

ESTADISTICA DESCRIPTIVA
Una vez que se han recogido los valores que toman las variables de nuestro estudio (datos), procederemos al análisis descriptivo de los mismos. Para variables categóricas, como el sexo o el estadiaje, se quiere conocer el número de casos en cada una de las categorías, reflejando habitualmente el porcentaje que representan del total, y expresándolo en una tabla de frecuencias.
Para variables numéricas, en las que puede haber un gran número de valores observados distintos, se ha de optar por un método de análisis distinto, respondiendo a las siguientes preguntas:
Las medidas de centralización vienen a responder a la primera pregunta. La medida más evidente que podemos calcular para describir un conjunto de observaciones numéricas es su valor medio. La media no es más que la suma de todos los valores de una variable dividida entre el número total de datos de los que se dispone.
Como ejemplo, consideremos 10 pacientes de edades 21 años, 32, 15, 59, 60, 61, 64, 60, 71, y 80. La media de edad de estos sujetos será de:
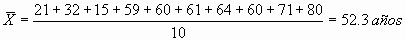
Más formalmente, si denotamos por (X1, X2,...,Xn) los n datos que tenemos recogidos de la variable en cuestión, el valor medio vendrá dado por:
Para variables numéricas, en las que puede haber un gran número de valores observados distintos, se ha de optar por un método de análisis distinto, respondiendo a las siguientes preguntas:
- ¿Alrededor de qué valor se agrupan los datos?
- Supuesto que se agrupan alrededor de un número, ¿cómo lo hacen? ¿muy concentrados? ¿muy dispersos?
Las medidas de centralización vienen a responder a la primera pregunta. La medida más evidente que podemos calcular para describir un conjunto de observaciones numéricas es su valor medio. La media no es más que la suma de todos los valores de una variable dividida entre el número total de datos de los que se dispone.
Como ejemplo, consideremos 10 pacientes de edades 21 años, 32, 15, 59, 60, 61, 64, 60, 71, y 80. La media de edad de estos sujetos será de:
Más formalmente, si denotamos por (X1, X2,...,Xn) los n datos que tenemos recogidos de la variable en cuestión, el valor medio vendrá dado por:

Otra medida de tendencia central que se utiliza habitualmente es la mediana. Es la observación equidistante de los extremos.
La mediana del ejemplo anterior sería el valor que deja a la mitad de los datos por encima de dicho valor y a la otra mitad por debajo. Si ordenamos los datos de mayor a menor observamos la secuencia:
15, 21, 32, 59, 60, 60,61, 64, 71, 80.
Como quiera que en este ejemplo el número de observaciones es par (10 individuos), los dos valores que se encuentran en el medio son 60 y 60. Si realizamos el cálculo de la media de estos dos valores nos dará a su vez 60, que es el valor de la mediana.
Si la media y la mediana son iguales, la distribución de la variable es simétrica. La media es muy sensible a la variación de las puntuaciones. Sin embargo, la mediana es menos sensible a dichos cambios.
Por último, otra medida de tendencia central, no tan usual como las anteriores, es la moda, siendo éste el valor de la variable que presenta una mayor frecuencia.
En el ejemplo anterior el valor que más se repite es 60, que es la moda
b. Medidas de dispersión
Tal y como se adelantaba antes, otro aspecto a tener en cuenta al describir datos continuos es la dispersión de los mismos. Existen distintas formas de cuantificar esa variabilidad. De todas ellas, la varianza (S2) de los datos es la más utilizada. Es la media de los cuadrados de las diferencias entre cada valor de la variable y la media aritmética de la distribución.

Esta varianza muestral se obtiene como la suma de las de las diferencias de cuadrados y por tanto tiene como unidades de medida el cuadrado de las unidades de medida en que se mide la variable estudiada.
En el ejemplo anterior la varianza sería:
La desviación típica (S) es la raíz cuadrada de la varianza. Expresa la dispersión de la distribución y se expresa en las mismas unidades de medida de la variable. La desviación típica es la medida de dispersión más utilizada en estadística.
Sx2=

Aunque esta fórmula de la desviación típica muestral es correcta, en la práctica, la estadística nos interesa para realizar inferencias poblacionales, por lo que en el denominador se utiliza, en lugar de n, el valor n-1.
Por tanto, la medida que se utiliza es la cuasidesviación típica, dada por:

Aunque en muchos contextos se utiliza el término de desviación típica para referirse a ambas expresiones.
En los cálculos del ejercicio previo, la desviación típica muestral, que tiene como denominador n, el valor sería 20.678. A efectos de cálculo lo haremos como n-1 y el resultado seria 21,79.
El haber cambiado el denominador de n por n-1 está en relación al hecho de que esta segunda fórmula es una estimación más precisa de la desviación estándar verdadera de la población y posee las propiedades que necesitamos para realizar inferencias a la población.
Cuando se quieren señalar valores extremos en una distribución de datos, se suele utilizar la amplitud como medida de dispersión. La amplitud es la diferencia entre el valor mayor y el menor de la distribución.
Por ejemplo, utilizando los datos del ejemplo previo tendremos 80-15 =65.
Como medidas de variabilidad más importantes, conviene destacar algunas características de la varianza y desviación típica:
Otra medida que se suele utilizar es el coeficiente de variación (CV). Es una medida de dispersión relativa de los datos y se calcula dividiendo la desviación típica muestral por la media y multiplicando el cociente por 100. Su utilidad estriba en que nos permite comparar la dispersión o variabilidad de dos o más grupos. Así, por ejemplo, si tenemos el peso de 5 pacientes (70, 60, 56, 83 y 79 Kg) cuya media es de 69,6 kg. y su desviación típica (s) = 10,44 y la TAS de los mismos (150, 170, 135, 180 y 195 mmHg) cuya media es de 166 mmHg y su desviación típica de 21,3. La pregunta sería: ¿qué distribución es más dispersa, el peso o la tensión arterial? Si comparamos las desviaciones típicas observamos que la desviación típica de la tensión arterial es mucho mayor; sin embargo, no podemos comparar dos variables que tienen escalas de medidas diferentes, por lo que calculamos los coeficientes de variación:
CV de la variable peso =
CV de la variable TAS =
A la vista de los resultados, observamos que la variable peso tiene mayor dispersión.
Cuando los datos se distribuyen de forma simétrica (y ya hemos dicho que esto ocurre cuando los valores de su media y mediana están próximos), se usan para describir esa variable su media y desviación típica. En el caso de distribuciones asimétricas, la mediana y la amplitud son medidas más adecuadas. En este caso, se suelen utilizar además los cuartiles y percentiles.
Los cuartiles y percentiles no son medidas de tendencia central sino medidas de posición. El percentil es el valor de la variable que indica el porcentaje de una distribución que es igual o menor a esa cifra.
Así, por ejemplo, el percentil 80 es el valor de la variable que es igual o deja por debajo de sí al 80% del total de las puntuaciones. Los cuartiles son los valores de la variable que dejan por debajo de sí el 25%, 50% y el 75% del total de las puntuaciones y así tenemos por tanto el primer cuartil (Q1), el segundo (Q2) y el tercer cuartil (Q3).
PROBABILIDAD CONDICIONAL E INDEPENDIENTE
Probabilidad condicionada
De Wikipedia, la enciclopedia libre
Probabilidad condicionada es la probabilidad de que ocurra un evento A, sabiendo que también sucede otro evento B. La probabilidad condicional se escribe P(A|B), y se lee «la probabilidad de A dado B.
No tiene por qué haber una relación causal o temporal entre A y B. A puede preceder en el tiempo a B, sucederlo o pueden ocurrir simultáneamente. A puede causar B, viceversa o pueden no tener relación causal. Las relaciones causales o temporales son nociones que no pertenecen al ámbito de la probabilidad. Pueden desempeñar un papel o no dependiendo de la interpretación que se le dé a los eventos.
El condicionamiento de probabilidades puede lograrse aplicando el teorema de Bayes.
Definición
Dado un espacio de probabilidad (Ω,F,P) y dos eventos (o sucesos) con P(B) > 0, la probabilidad condicional de A dado B está definida como:
con P(B) > 0, la probabilidad condicional de A dado B está definida como:

 se puede interpretar como, tomando los mundos en los que B se cumple, la fracción en los que también se cumple A.
se puede interpretar como, tomando los mundos en los que B se cumple, la fracción en los que también se cumple A.Interpretación
se puede interpretar como, tomando los mundos en los que B se cumple, la fracción en los que también se cumple A. Si el evento B es, por ejemplo, tener la gripe, y el evento A es tener dolor de cabeza, sería la probabilidad de tener dolor de cabeza cuando se está enfermo de gripe.Gráficamente, si se interpreta el espacio de la ilustración como el espacio de todos los mundos posibles, A serían los mundos en los que se tiene dolor de cabeza y B el espacio en el que se tiene gripe. La zona verde de la intersección representaría los mundos en los que se tiene gripe y dolor de cabeza
 . En este caso , es decir, la probabilidad de que alguien tenga dolor de cabeza sabiendo que tiene gripe, sería la proporción de mundos con gripe y dolor de cabeza (color verde) de todos los mundos con gripe: El área verde dividida por el área de B. Como el área verde representa y el área de B representa a P(B), formalmente se tiene que:
. En este caso , es decir, la probabilidad de que alguien tenga dolor de cabeza sabiendo que tiene gripe, sería la proporción de mundos con gripe y dolor de cabeza (color verde) de todos los mundos con gripe: El área verde dividida por el área de B. Como el área verde representa y el área de B representa a P(B), formalmente se tiene que:Propiedades


Pero NO es cierto que


Independencia de sucesos
Dos sucesos aleatorios A y B son independientes si y sólo si: ó P(A,B).
ó P(A,B).puede ser expresada como el producto de las probabilidades individuales. Equivalentemente:

Exclusividad mutua

 . Entonces,
. Entonces,  .
.Además, si P(B) > 0 entonces
es igual a 0.La falacia de la probabilidad condicional
La falacia de la probabilidad condicional se basa en asumir que P(A|B) es casi igual a P(B|A). El matemático John Allen Paulos analiza en su libro El hombre anumérico este error muy común cometido por doctores, abogados y otras personas que desconocen la probabilidad.La verdadera relación entre P(A|B) y P(B|A) es la siguiente:
 (
(Problemas de ejemplo
---La paradoja del falso positivo---La magnitud de este problema es la mejor entendida en términos de probabilidades condicionales.
Supongamos un grupo de personas de las que el 1 % sufre una cierta enfermedad, y el resto está bien. Escogiendo un individuo al azar:
P(enfermo) = 1% = 0.01 y P(sano) = 99% = 0.99
Supongamos que aplicando una prueba a una persona que no tiene la enfermedad, hay una posibilidad del 1 % de conseguir un falso positivo, esto es:
P(positivo | sano) = 1% y P(negativo | sano) = 99%
Finalmente, supongamosque aplicando la prueba a una persona que tiene la enfermedad, hay una posibilidad del 1 % de un falso negativo, esto es:
P(negativo | enfermo) = 1% y P(positivo | enfermo) = 99%
Ahora, uno puede calcular lo siguiente:
La fracción de individuos en el grupo que están sanos y dan negativo:

La fracción de individuos en el grupo que están enfermos y dan positivo:

La fracción de individuos en el grupo que dan falso positivo:

La fracción de individuos en el grupo que dan falso negativo:

Además, la fracción de individuos en el grupo que dan positivo:

Finalmente, la probabilidad de que un individuo realmente tenga la enfermedad, dado un resultado de la prueba positivo:

En este ejemplo, debería ser fácil ver la diferencia entre las probabilidades condicionadas P (positivo | enfermo) (que es del 99 %) y P (enfermo | positivo) (que es del 50 %): la primera es la probabilidad de que un individuo enfermo de positivo en la prueba; la segunda es la probabilidad de que un individuo que da positivo en la prueba tenga realmente la enfermedad. Con los números escogidos aquí, este último resultado probablemente sería considerado inaceptable: la mitad de la gente que da positivo en realidad está sana.
La probabilidad de tener una enfermedad rara es de 0,001: P(enfermo) = 0,001
La probabilidad de que cuando el paciente está enfermo se acierte en el diagnóstico es de 0,99: P(positivo | enfermo) = 0,99
La probabilidad de falso positivo es de 0,05: P(positivo | sano) = 0,05
Pregunta: Me dicen que he dado positivo, ¿Qué probabilidad hay de que tenga la enfermedad?



Probabilidad Independiente
De Wikipedia, la enciclopedia libre
En teoría de probabilidades, se dice que dos sucesos aleatorios son independientes entre sí cuando la probabilidad de cada uno de ellos no está influida por que el otro suceso ocurra o no, es decir, cuando ambos sucesos no están correlacionados.Definición formal
Dos sucesos son independientes si la probabilidad de que ocurran ambos simultáneamente es igual al producto de las probabilidades de que ocurra cada uno de ellos, es decir, si A y B son dos sucesos, y P(A) y P(B) son las probabilidades de que ocurran respectivamente entonces:A y B son independientes si y solo si |

Motivación de la definición
Sean A y B dos sucesos tales que P(B) > 0, intuitivamente A es independiente de B si la probabilidad de A condicionada por B es igual a la probabilidad de A. Es decir si: y dado que
y dado que  deducimos trivialmente que
deducimos trivialmente que  .
.Si el suceso A es independiente del suceso B, automáticamente el suceso B es independiente de A.
Propiedades
La independencia de sucesos es algo muy importante para la estadística y es condición necesaria en multitud de teoremas. Por ejemplo, una de las primeras propiedades que se deriva de la definición de sucesos independientes es que si dos sucesos son independientes entre sí, la probabilidad de la intersección es igual al producto de las probabilidades.
Suscribirse a:
Entradas (Atom)
